
AI4ScaDa: KI sichert Wissen und findet das richtige Produkt
Ob bei der Raffination von Speiseöl, oder der Herstellung von Obstsäften und Weinen: Dekanter und Seperatoren trennen Flüssigkeiten in ihre unterschiedlichen Bestandteile und sind deshalb für Prozesse beispielsweise in der Nahrungsmittelindustrie oder in der Chemie unerlässlich. Ein deutscher Hersteller von Separatoren und Dekantern ist die GEA Westfalia Separator Group GmbH mit Hauptsitz in Oelde. Im it’s OWL Projekt AI4ScaDa untersucht das Unternehmen wie mit Hilfe von Künstlicher Intelligenz (KI) das Wissen im Unternehmen gesichert werden kann. Und wie KI sogar Außendienstmitarbeitende unterstützen kann, das richtige Produkt für den jeweiligen Kunden zu finden.
Was macht GEA?
GEA ist einer der weltweit größten Anbieter für Systeme und Prozesse beispielsweise für die mechanische Klärung und Trennung von Flüssigkeiten in der Nahrungsmittelindustrie, Chemie, Pharmazie, Biotechnologie, Energie-, Schifffahrt- und Umwelttechnik. Für die mechanische Klärung werden zwei unterschiedliche Zentrifugenarten, Dekanter und Separatoren, eingesetzt. Die Flüssigkeiten beinhalten unterschiedliche Bestandteile (z.B. Partikel und unterschiedliche Fluidphasen), welche von den Dekantern und Separatoren aufgrund ihres Dichteunterschieds voneinander getrennt werden können. Abbildung 2 zeigt das Separationsergebnis einer Produktprobe, welche in einen festen und einen flüssigen Bestandteil getrennt werden kann. Anwendungen finden sich unter anderem bei der Raffination und Gewinnung von Speiseöl, bei der Herstellung von Milch und Milchprodukten, Bier, Wein, Obst- und Gemüsesäften, Stärke und Proteinen sowie bei der Reinigung und Aufbereitung von Mineralöl und Mineralölprodukten.

Was soll mit KI bei der Zentrifugenauslegung erreicht werden?
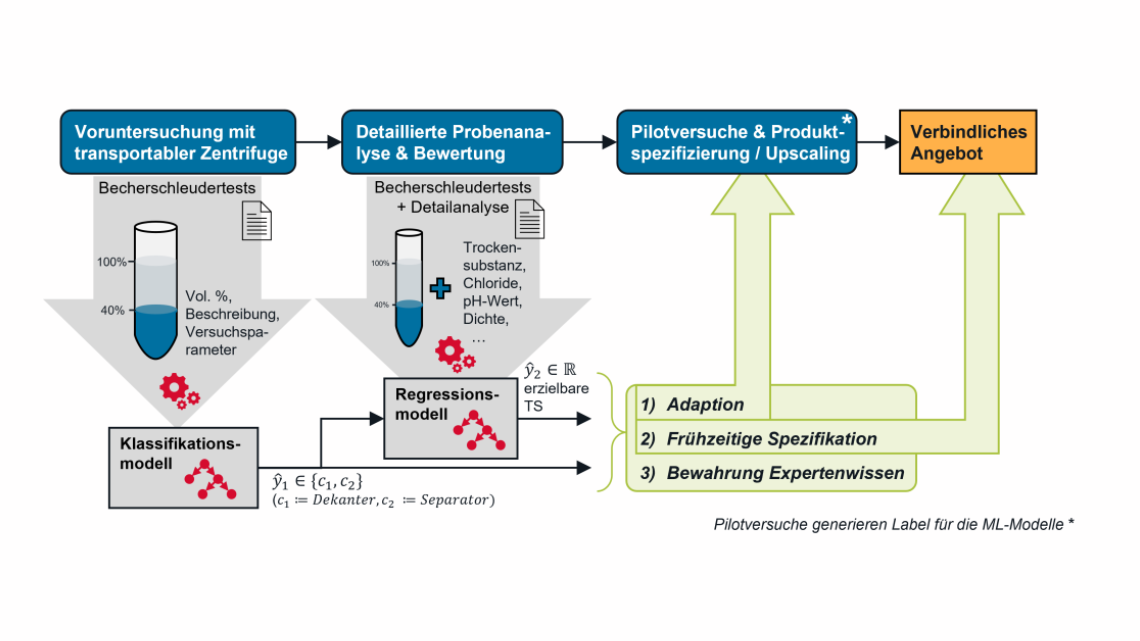
Für eine Produktauslegung werden Flüssigkeitsproben vom Kunden zur Verfügung gestellt, die von den Expert:innen bei GEA im Labor hinsichtlich ihrer Separierbarkeit untersucht werden. Basierend auf den Laborergebnissen wird eine mögliche Zentrifugenart (Dekanter oder Separator) für die Separation der Probe vorgeschlagen, die im Rahmen eines Pilotversuchs unter Realbedingungen erprobt und dimensioniert wird. Anschließend wird dem Kunden ein verbindliches Produktangebot für eine Zentrifuge inklusive der damit erzielbaren Separationsleistungen unterbreitet. Die Bewertung der Separierbarkeit, die Auswahl der Zentrifugenart und die Wahl der durchzuführenden Analysen im Labor und bei den Pilotversuchen basieren allesamt auf Expertenwissen, welches die Laboringenieur:innen über Jahrzehnte aufgebaut haben. Aufgrund des demografischen Wandels werden allerdings viele Laboringenieur:innen in absehbarer Zeit in Rente gehen. Aus diesem Grund ist es wichtig, deren Expertenwissen mittels KI in datenbasierten Modellen zu verdichten und zu bewahren, aber auch neuen Mitarbeiter:innen zur Verfügung zu stellen.
Die datenbasierten Modelle sollen zudem für eine KI-getriebene Produktauslegung eingesetzt werden, die die Außendienstmitarbeiter von GEA bei einer frühzeitigen Spezifikation der Separierbarkeit und der Zentrifugenart beim Kunden vor Ort unterstützt und Einstellungsparameter für die durchzuführenden Pilotversuche vorschlägt. Letztendlich können dadurch Kosten und Zeit für weitere Tests und Versuche eingespart werden und Untersuchungen können frühzeitig adaptiert oder abgebrochen werden, wenn der Produktvorschlag nicht den Erwartungen des Kunden entspricht. Das Zielbild dieses Use-Cases ist in der Abbildung 3 dargestellt.
Was sind die Herausforderungen bei GEA?
Die Daten sind nur schwer zu erhalten, da viele Informationen als Fließtext und ein Großteil der historischen Daten als Scan vorliegen. Außerdem müssen für die historischen Daten die jeweiligen Labor- und Pilotversuchsberichte durch Expertenwissen einander zugeordnet werden. Das hat zur Folge, dass ein Großteil der verfügbaren Daten ungelabelt ist. Weil die durchzuführenden Untersuchungen von den Eigenschaften der Flüssigkeitsproben und den Kundenanforderungen abhängen, sind die verfügbaren Daten zudem sehr heterogen. Infolgedessen kann nur auf eine geringe Datenbasis (Scarce Data) zugegriffen werden. Eine weitere Herausforderung besteht in der Unschärfe der im Bericht enthaltenen Informationen. Die Analyseergebnisse können zum Teil nur subjektiv bewertet werden und Eigenschaften der Flüssigkeitsprobe sind nicht immer vollständig spezifizierbar oder variieren zwischen den Labor- und Pilotversuchen. Zudem können viele Flüssigkeitsproben sowohl mit Dekantern als auch mit Separatoren getrennt bzw. geklärt werden.
Wie will das Projektteam diesen Herausforderungen begegnen?
Die datenbasierten Modelle, die auf einem initialen Datensatz erzeugt werden, sollen durch einen aktiven Lernansatz mit augmentierten Daten in Bereichen der Modellunsicherheit nachtrainiert werden. Die augmentierten Daten werden von mehreren Laboringenieur:innen simultan gelabelt und mit Methoden der Informationsfusion zu einem aussagekräftigen unscharfen Label aggregiert. Dadurch kann Expertenwissen im Modell gezielt integriert und die Unschärfe beim Einsatz von Dekantern und Separatoren abgebildet werden.
Im it’s OWL Innovationsprojekt AI4ScaDa werden spezielle KI-Methoden erforscht, die im Kontext von Scarce Data gewinnbringend eingesetzt werden können. Im Gegensatz zu Big Data steht Scarce Data für wenige oder lückenhafte aber häufig präzise Daten. Herausforderungen bestehen aber gerade darin, dass KI-Systeme sowohl stark von der Qualität als auch von der Quantität der Daten abhängen. Wo nur sehr spärliche Daten vorhanden sind, kann eine Großzahl der KI-Verfahren nur schwer mit menschlicher Expertise mithalten. Aktuelle Erkenntnisse bezüglich KI und Scarce Data werden im Projekt auf drei Use-Cases der Unternehmen Saaten-Union Biotec GmbH, GEA und Miele & Cie. KG weiterentwickelt, transferiert und operationalisiert. Forschungsseitig arbeiten das Center for Applied Data Sciences (CfADS) der HSBI und das Institut für industrielle Informationstechnik (inIT) der TH OWL im Projekt.








